Miraż wynagrodzeń, gdy AI myli się w kwestii płac

Liczby, ktore brzmią dobrze
Zapytaj dowolne AI, ile powinna płacić dana rola, a otrzymasz coś precyzyjnego: czyste przedziały, uporządkowane percentyle, pewny ton. Dla HR pod presją czasu i zespołów dążących do parytetów płacowych wygląda to jak postęp.
Zbyt często jednak te liczby pochodzą ze słabych źródeł – zescrapowanych ogłoszeń, niejasnych tytułów, nieaktualnych próbek i modeli wytrenowanych, by brzmieć wiarygodnie, a nie by takimi być. Gdy zapytasz o źródła, okna czasowe czy zasady normalizacji, pewność wyparowuje. Brak powtarzalnej metody. Brak hierarchii źródeł. Brak śladu audytowego.
Efekt? Pewność siebie wyprzedza wiarygodność. Domysły twardnieją w "rynkowe" benchmarki, a organizacje płacą za to wysoką cenę.
Ta seria bada, dlaczego te liczby brzmią dobrze, ale często takimi nie są, i jak odrożnić jedno od drugiego. Curioz przyglāda siē, co weryfikować, co naprawdē oznacza przejrzystość, i jakie praktyki danych pozwalajā utrzymać decyzje płacowe w zgodzie z prawdą.
Precyzyjnie niepewne
Duże modele językowe (LLM) to nowy cheat code do praktycznych pytań, w tym o wynagrodzenia. Zapytaj: "Jaka jest pensja Senior DevOps Engineer z 6+ latami doświadczenia, pracującego na pełny etat i zdalnie, w Polsce?" i bum – w minucie pojawia się pewnie wyglądająca, dobrze sformatowana odpowiedź. Żadnych zakurzonych raportów benchmarkingowych. Żadnego ręcznego ciągnięcia danych. Żadnych arkuszy kalkulacyjnych. Brzmi jak marzenie… prawie zbyt pięknie. Więc w czym haczyk?
Jesteśmy z natury Curioz, nie mogliśmy się oprzeć testom. Postawiliśmy te pytania:
- Czy model faktycznie daje ci liczby, na których możesz opierać decyzje biznesowe?
- Co jeśli uruchomisz ten sam prompt wielokrotnie, w nowych sesjach i z wyczyszczoną pamięcią podręczną?
- Czy liczby rozsądnie się zgadzają, czy zmieniają się znacząco za każdym razem?
Przeprowadziliśmy więc prosty test. Bez zaglądania pod maskę. Bez "wyjaśnij swoją metodologię", bez "ile ogłoszeń o pracę sprawdziłeś?" czy "które portale przeglądałeś?". Po prostu poprosiliśmy AI o przeanalizowanie aktualnych ogłoszeń o pracę z bieżącego miesiąca i zwrot trzech liczb: niski, medianowy i wysoki przedział wynagrodzenia dla tej roli.
Celem była spójność. Nie eksperyment laboratoryjny, nie dostęp od wewnątrz, po prostu zwykli użytkownicy, naciskający Enter jak wszyscy inni.
Skrót zbyt piękny, by być prawdziwy
Zadaliśmy AI to samo pytanie o wspomnianego Senior DevOps Engineer wiele razy w nowych czatach, z wyczyszczoną pamięcią podręczną. Za każdym razem generowało liczby dla niskiego, medianowego i wysokiego wynagrodzenia w ujęciu B2B godzinowym, dziennym i UoP miesięcznym w tej samej odpowiedzi. Trzy wykresy przedstawiają te powtarzane odpowiedzi, abyś mógł zobaczyć, jak bardzo wyniki wahają się między kolejnymi uruchomieniami.
- Niski ≈ co mniejsze lub bardziej konserwatywne firmy mogą oferować (około 25. percentyla).
- Mediana = środek rynku (50. percentyl).
- Wysoki = mocne, ale wciąż realistyczne oferty (w przybliżeniu 75.–90. percentyl).
Co się więc dzieje, gdy zadajesz AI to samo pytanie w kółko? Spójrzmy.
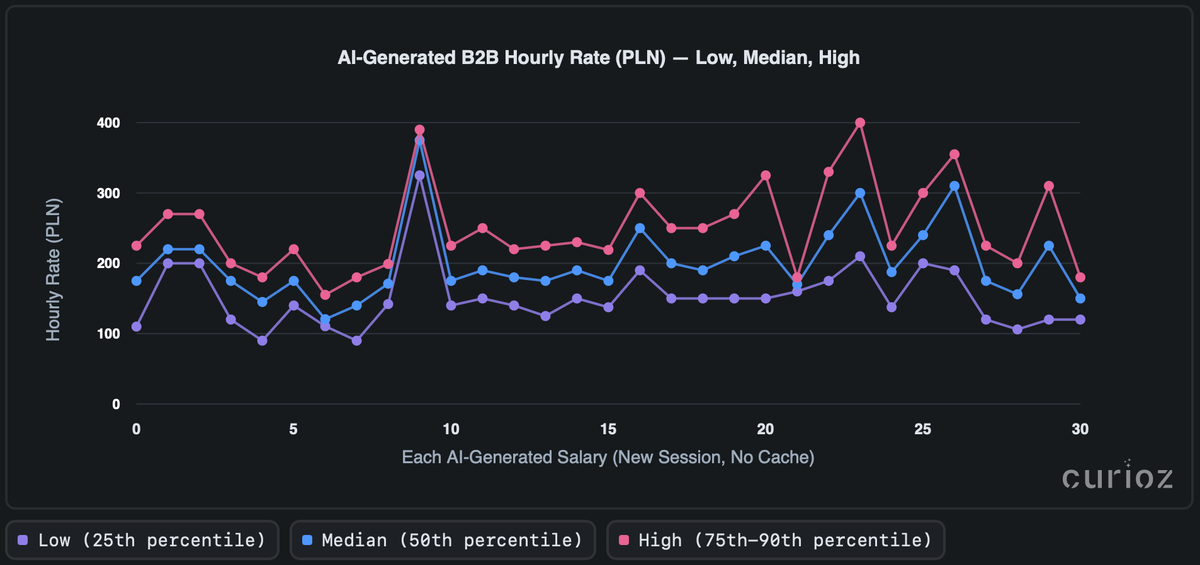
W wielu uruchomieniach szacunkowe stawki godzinowe mogą wyglądać, jakby skupiały się wokół ~153 PLN/h, ~203 PLN/h i ~253 PLN/h. Jednak ponad połowa par uruchomień różni się o 25–30% lub więcej, co wskazuje na istotną zmienność.
Pojedyncze iteracje mogą odchylać się o 40–50 PLN/h, z okazjonalnymi odchyleniami w zakresie od 100 PLN/h do 400 PLN/h. Linie stawek wahają się zauważalnie między sesjami; niektóre uruchomienia wydają się systematycznie bardziej hojne, podczas gdy inne są bardziej konserwatywne. Ogólnie rozrzut pokazuje niepokojącą zmienność i obecność wartości odstających.
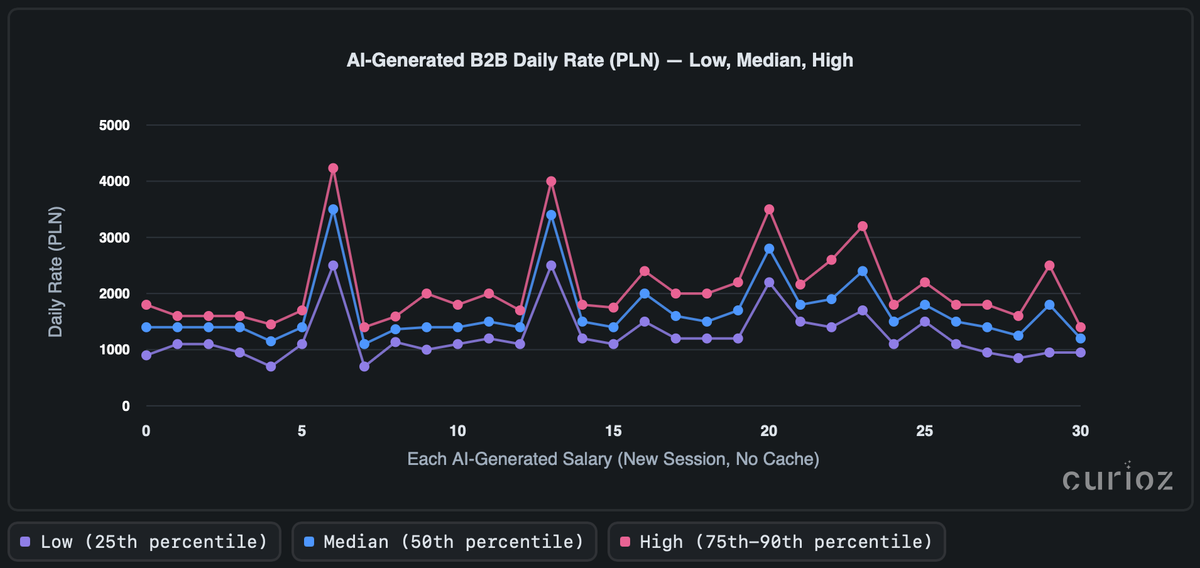
Wyniki stawek dziennych pokazują coś, co może wyglądać jak typowa strefa stabilności przerywana ostrymi, nieregularnymi skokami. Przy bliższym przyjrzeniu się poszczególne szczyty różnią się o setki PLN, czasami przekraczając 4 000 PLN/dzień na górnym krańcu. Chociaż takie wyniki mogą wyglądać wiarygodnie w izolacji, porównania obok siebie ujawniają je jako wyraźne wartości odstające. W przybliżeniu 70% powtarzanych "identycznych" uruchomień różni się o ≥25%, co potwierdza istotną niespójność między uruchomieniami. W praktyce oznacza to, że wyników z pojedynczego uruchomienia nie można traktować jako stabilnych wskaźników.
Gdy spojrzysz na wykresy stawek godzinowych i dziennych, jasne jest, że się nie zgadzają. Można by oczekiwać, że stawka dzienna w pewnym stopniu odpowiada stawce godzinowej pomnożonej przez standardową liczbę godzin pracy. Jednak widoczne jest, że AI wygenerowało stawkę dzienną niezależnie. Chociaż stawki dzienne stają się coraz powszechniejsze w ofertach pracy, ta rozbieżność może być myląca dla profesjonalistów zajmujących się benchmarkingiem, zwłaszcza że pomnożenie średniej stawki godzinowej przez osiem godzin daje wartości stawek dziennych odchylające się nawet o 40%.
Z drugiej strony, powtarzane testy dla kontraktów opartych na umowie o pracę (UoP) również ujawniają niestabilne zachowanie wyników. Większość szacunków mieści się w paśmie zmienności ~900 PLN, ale ślad oscyluje w górę i w dół, czasami wahając się o kilka tysięcy PLN. Klasteryzacja jest widoczna, ale z dużym rozrzutem wewnętrznym, a pojedyncze uruchomienia czasami skaczą o setki do ponad 2 000 PLN. W przybliżeniu jedna trzecia nominalnie identycznych zapytań istotnie się różni, przy czym mediana i górne kwantyle wykazują najszerszy rozrzut.
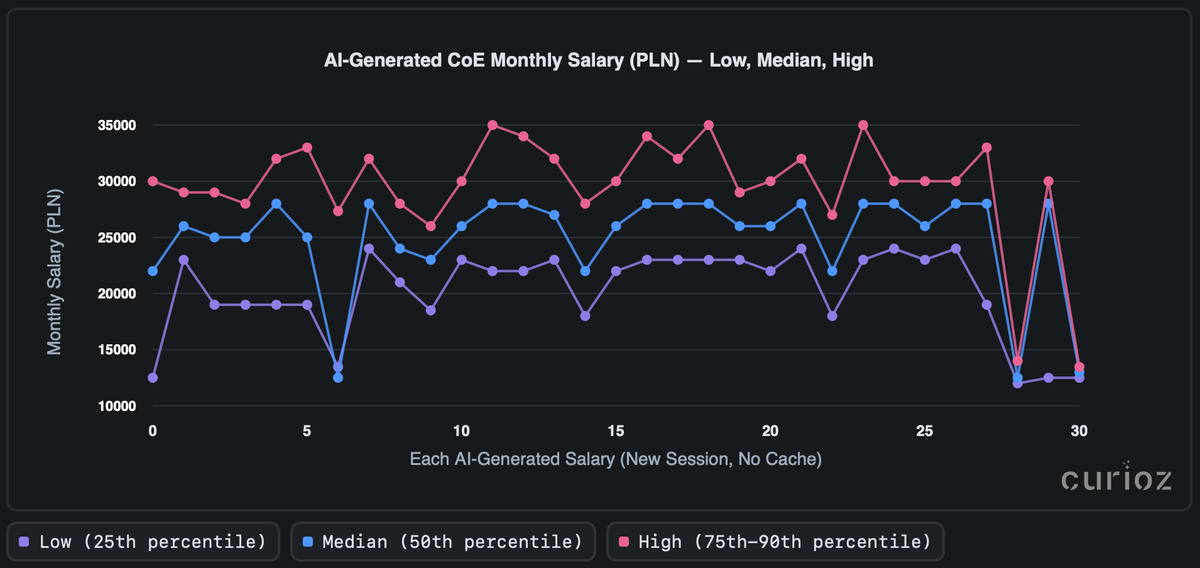
W wynikach nie ma pewnych klasterów. Nawet przy tym samym prompcie i konfiguracji wyniki różnią się istotnie między uruchomieniami, co wskazuje, że AI nie jest spójne i nie korzysta za każdym razem z dokładnie tych samych dowodów.
Czy stać Cię na zaufanie swojemu promptowi?
Mając te dowody, naturalnie pojawia się pytanie: czy możesz zaufać swojemu promptowi w podejmowaniu decyzji biznesowych?
Gdy identyczne dane wejściowe AI produkują istotnie różne wyniki, zaufanie do jakiegokolwiek pojedynczego wyniku staje się zawodne. Dla osoby odpowiedzialnej za ustalanie wynagrodzeń lub wycenę ról, ta niespójność ma realne konsekwencje finansowe.
Które liczby wybrać?
"Mała" różnica 100 PLN dziennie staje się kilkoma tysiącami PLN miesięcznie na pracownika. W skali zespołu to narastają dziesiątki lub setki tysięcy w odchyleniu budżetowym. Godzinowe wahania o 40–50 PLN zniekształcają oferty i kontrakty. W przypadku miesięcznych wynagrodzeń nawet 10-15% odchylenie może oznaczać różnicę między konkurencyjnymi ofertami a kosztownym błędnym wycenieniem. Niezależnie od tego, czy zatrudniasz Data Engineers, AI Engineers, QA Automation Engineers czy jakiegokolwiek innego specjalistę IT, właściwy benchmarking wynagrodzeń może być grą o zysk lub stratę. Błędna wycena oferty uruchamia kaskadę: dłuższe cykle rekrutacyjne, odpadanie kandydatów i ghosting; wyższą rotację i koszty ponownej rekrutacji; przepyłacanie, które rozsadza siatki płac, tworzy kompresję wynagrodzeń i nadyma budżety; renegocjacje kontraktów, zniekształcone oferty przetargowe i nieosiagniete cele. Napraw benchmark, a ograniczysz straty na dalszych etapach.
Ten efekt domina ma lekarstwo – realne dane rynkowe. Curioz jest zbudowane na rzeczywistości, nie na spekulacji AI. Analizujemy tysiące ofert pracy, podpisanych kontraktów i danych partnerskich każdego miesiąca. Nasze dane pochodzą z zaobserwowanych dowodów rynkowych i zweryfikowanych statystyk, nie z uruchomień AI. Nasze liczby są spójne, obronne i gotowe do podejmowania decyzji.
Gdy decyzje dotyczą milionów, nie możesz sobie pozwolić na zgadywanie.
Talent-as-a-Service (TaaS): kompetencje na żądanie, kumulujący się wpływ
W 2025 roku wygrywają szybkość, jasność i zdolność adaptacji. TaaS daje elastyczny dostęp do dokładnie tych kompetencji, których potrzebujesz, wtedy gdy ich potrzebujesz, dzięki czemu praca posuwa się szybciej, decyzje są trafniejsze, a wyniki poprawiają się bez zwiększania stałego zatrudnienia.
Dlaczego TaaS?
- Szybsze wyniki → Uruchomienie inicjatyw w tygodnie, nie kwartały.
- Elastyczna wydajność → Skalowanie w górę lub w dół wraz ze zmieniającymi się priorytetami.
- Jasna odpowiedzialność → Współpraca oparta na wynikach z mierzalnymi celami.
- Niższe ryzyko → Próbuj, ucz się i adaptuj bez długoterminowych zobowiązań.
- Płynna integracja → Talent włącza się w Twoje procesy, narzędzia i kulturę.
Wzorzec współpracy 30/60/90
- 0–30 dni: Dopasowanie i udowodnienieOdkrywanie, ustalanie celów, przegląd stanu bieżącego, szybkie wygrane i jasny plan sukcesu.
- 31–60 dni: Budowanie i walidacjaRealizacja planu, rozszerzanie zakresu tam, gdzie działa, walidacja wyników względem uzgodnionych metryk.
- 61–90 dni: Skalowanie i osadzanieOperacjonalizacja tego, co działa, ustanowienie zarządzania i przekazywania, wspieranie Twojego zespołu oraz optymalizacja kosztów i wydajności.
Gdzie to pomaga?
Strategia, operacje, produkt, marketing, finanse, ryzyko, ludzie i każda funkcja, która potrzebuje skoncentrowanej ekspertyzy, aby przyspieszyć wyniki.
Konkurenci już kumulują przewagi dzięki elastycznym modelom talentowym. Dodaj TaaS teraz, aby działać szybciej, pozostawać elastycznym i zamieniaj priorytety w postęp co kwartał.
UWAGA: Ten wpis oparty jest na badaniach Inuits.it i Curioz.io i został opublikowany na obu platformach.
Chcesz z nami współpracować?
Porozmawiajmy o tym, jak możemy pomóc Twojemu zespołowi dostarczać szybciej.
Komentarze
Podziel się swoimi przemyśleniami.


