Zrozumieć stanowiska w branży AI i danych w 2025 roku: Praktyczny przewodnik dla Talent-as-a-Service

W miarę jak sztuczna inteligencja przekształca każdy aspekt IT, tytuły stanowisk w obszarze danych/AI pomnożyły się i wprowadziły zamieszanie zarówno wśród kandydatów, jak i menedżerów ds. rekrutacji. W Inuits nasze podejście Talent-as-a-Service (TaaS) opiera się na posiadaniu jasnych, realistycznych definicji tego, co te role robiądziś – a nie tylko tego, co sugeruje szum medialny.

Autor zdjęcia: Precessor, via flickr.com
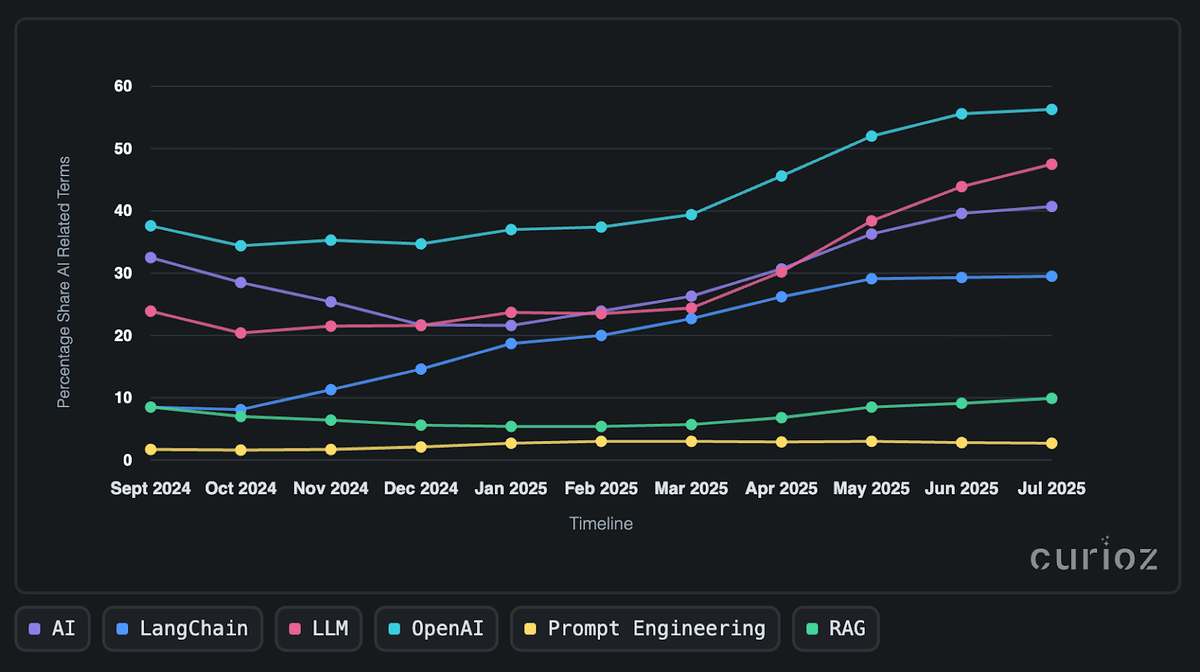
Chociaż firmy wciąż eksperymentują z rolami opartymi na AI, pewne wyraźne wzorce już się wyłoniły. Zacznijmy od najważniejszego. W połowie 2023 roku wpływowy wpis na blogu Latent.space naliczył około 10 razy więcej ML Engineers vs AI Engineers na Indeed, ale przewidział odwrócenie tego stosunku w 5 lat. Dwa lata później rzeczywistość stała się bardziej zniuansowana – 18 tys. ofert dla ML Engineer i około 11 tys. dla AI Engineer.
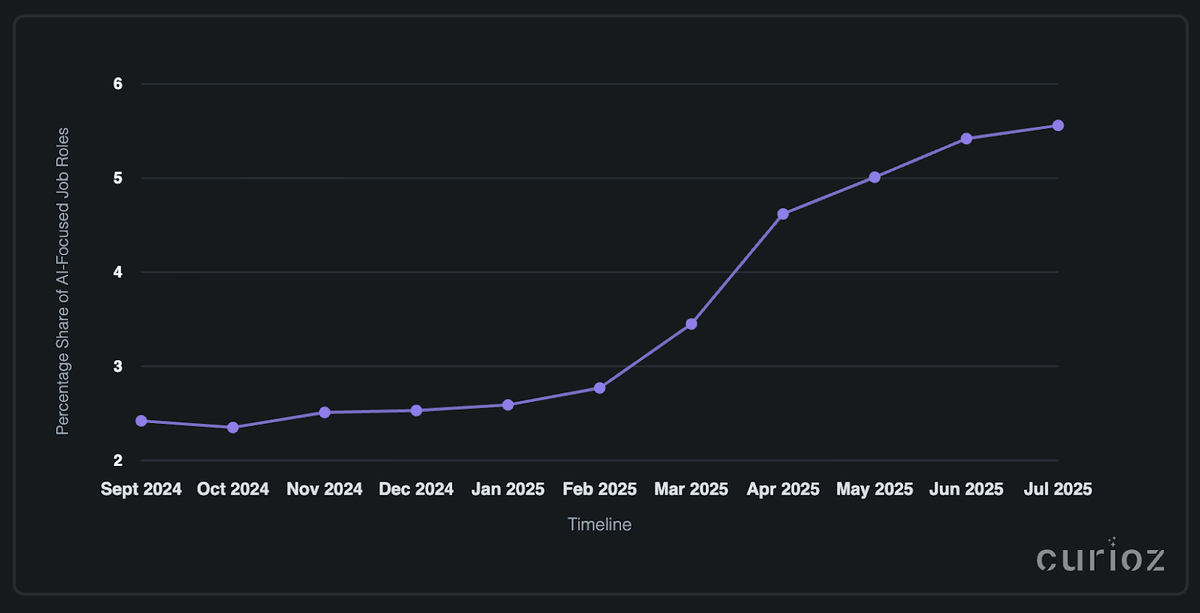
Dane z Curioz pokazują, że polski rynek pracy AI przeszedł od stabilności do sprintu. Pod koniec 2024 roku około 2,4% wszystkich ofert pracy było skoncentrowanych na AI, z niewielkimi miesięcznymi zmianami, odzwierciedlającymi niszowy, ale stabilny popyt. Początek 2025 przyniósł gwałtowny wzrost rekrutacji – skok z 2,77% w lutym do 4,62% w kwietniu i osiągnięcie 5,56% w lipcu, ponad dwukrotnie więcej niż we wrześniu ubiegłego roku. Najszybszy wzrost nastąpił między lutym a kwietniem, prawdopodobnie napędzany nowymi budżetami korporacyjnymi, uruchomieniami dużych projektów AI i możliwie rządowymi lub unijnymi programami finansowania. Ten szybki wzrost sugeruje, że adopcja AI w Polsce przesuwa się od eksperymentowania do wdrażania na dużą skalę, a firmy aktywnie budują dedykowane zespoły AI. Role AI nie są już niszowe – stają się kluczową częścią rynku, a impet wskazuje, że ich udział może nadal rosnąć przez resztę 2025 roku.
Tymczasem pojawiają się zupełnie nowe tytuły – widzimy pojawienie się Prompt Engineers, Generative AI Engineers, a nawet GPT Engineers.
Kim są i dlaczego?
Rys. 1: Procentowy udział ról AI w Polsce
Nasz pogląd, wzmocniony analizą z Curioz.io, jest taki, że prawie każdą pracę w AI i danych w 2025 roku można przyporządkować do sześciu ogólnych kategorii. Wszystko inne to albo modne hasło, albo niszowa specjalizacja, albo nakładający się tytuł.
Sześć głównych kategorii stanowisk AI/Data
- Data Analyst
Główny zakres: Interpretacja i wizualizacja danych w celu odpowiedzi na pytania biznesowe.Umiejętności: SQL, narzędzia BI (Tableau, Power BI, Looker), data storytelling.Narzędzia: Excel/Google Sheets, biblioteki wizualizacyjne, hurtownie oparte na SQL.Sprawdzian rzeczywistości: W kontekstach AI analitycy coraz częściej używają narzędzi BI wspieranych przez AI, ale nadal koncentrują się na dostarczaniu wniosków, nie na budowaniu modeli ML. - Data Engineer
Główny zakres: Projektowanie i utrzymywanie pipeline’ów danych, storage i procesów ETL.Umiejętności: Python/Scala, przetwarzanie rozproszone (Spark, Flink), orkiestracja (Airflow), infrastruktura danych w chmurze.Narzędzia: AWS/GCP/Azure usługi danych, dbt, Kafka.Sprawdzian rzeczywistości: Bez czystych, dobrze ustrukturyzowanych pipeline’ów danych projekty AI zatrzymują się, zanim się zaczną. - Data Scientist
Główny zakres: Budowanie modeli statystycznych i machine learning w celu wydobywania wniosków i tworzenia prognoz.Umiejętności: Python/R, scikit-learn, eksploracyjna analiza danych, statystyka, inżynieria cech.Narzędzia: Jupyter, Pandas, NumPy, notebooki chmurowe.Sprawdzian rzeczywistości: Często nakłada się z ML Engineer – główna różnica polega na tym, że Data Scientists spędzają więcej czasu na eksploracji i prototypowaniu, mniej na wdrażaniu. - ML / MLOps Engineer
Główny zakres: Produkcjonalizacja modeli ML. Wdrażanie, monitorowanie i utrzymywanie ich na skalę.Umiejętności: MLflow, Kubeflow, orkiestracja kontenerów (Docker/Kubernetes), CI/CD dla ML, monitoring modeli.Narzędzia: AWS SageMaker, Vertex AI, Azure ML, Triton Inference Server.Sprawdzian rzeczywistości: To jest krytyczne wąskie gardło; wiele projektów AI umiera po fazie eksperymentowania, ponieważ brakuje ludzi, którzy potrafią faktycznie wdrażać i utrzymywać modele niezawodnie. - AI Researcher
Główny zakres: Przesuwanie granic modeli i algorytmów – od trenowania dużych modeli językowych (LLM) po eksperymentowanie z nowymi architekturami.Umiejętności: Teoria deep learning, PyTorch/TensorFlow, CUDA, trening rozproszony, badania akademickie.Narzędzia: Hugging Face Transformers, niestandardowe pipeline’y treningowe, klastry obliczeniowe wysokiej wydajności.Sprawdzian rzeczywistości: Tylko niewielki ułamek firm trenuje modele fundamentalne od zera. Nawet większość badaczy buduje teraz na bazie open-source’owych LLM lub modeli od dużych graczy. - AI Engineer
Główny zakres: Integrowanie i adaptowanie istniejących modeli AI (często LLM) do produktów; budowanie otaczającej infrastruktury, jak pipeline’y retrieval, systemy embeddingów i prompty.Umiejętności: Rozwój backendowy (Python/Node/Java), wektorowe bazy danych (Pinecone, Weaviate), pipeline’y RAG, orkiestracja API, fine-tuning modeli.Narzędzia: OpenAI API, Hugging Face Inference API, LangChain/LlamaIndex, funkcje chmurowe.Sprawdzian rzeczywistości: Pomimo futurystycznego tytułu większość AI Engineers nie trenuje modeli. Podłączają się do istniejących i obudowują je aplikacjami. "Ciężkie" trenowanie modeli zwykle pozostaje w dużych laboratoriach AI.
A co z Prompt Engineers, Generative AI Engineers, GPT Engineers?
Nie są to osobne główne role; to zestawy umiejętności lub nisze w ramach powyższych kategorii:

- Prompt Engineering: Kluczowa umiejętność dla AI Engineers, Data Scientists, a nawet analityków używających LLM.
- Generative AI Engineer: Często po prostu AI Engineer pracujący z modelami generowania tekstu/obrazów/wideo.
- GPT Engineer: Modna odmiana tytułu dla kogoś budującego z API OpenAI.
Autor zdjęcia: Elon Musk na TED2022, via TED.com
Rozmyte granice: role "AI-Enabled"
W rzeczywistości granica między "ekspertem od AI" a "AI-enabled" jest rozmyta.Wielu "AI Engineers" i "AI-Enabled Backend Engineers" robi to samo: łączy istniejące modele z aplikacjami. Prawdziwe rozróżnienie nie dotyczy tytułu, ale:
- Głębokości wiedzy o AI.
- Umiejętności adaptowania/eksplorowania modeli vs. jedynie wywoływania API.
- Rozumienia infrastruktury do skalowania i monitorowania AI w produkcji.Przykłady:
- AI-enabled Backend Engineers budują API integrujące się z endpointami LLM, podobnie do tego, co robi wielu AI Engineers.
- AI-enabled Frontend Developers podłączają UI z wynikami generowanymi przez AI.
- Większość rynku w 2025 roku dotyczy stosowania istniejącego AI, a nie rozwijania go od zera.
- Hiperwyspecjalizowane role są rzadkie poza topowymi laboratoriami badawczymi.
- Ekspertyza MLOps i infrastrukturalna to najbardziej niedoceniany zestaw umiejętności – bez niej projekty AI nie skalują się.
Wskazówka dla zespołów Talent-as-a-Service:
Zacznij od tych sześciu funkcji jako kręgosłupa swojej strategii talentów AI/danych, następnie dodawaj umiejętności "AI-enabled" i niszową ekspertyzę w miarę potrzeb projektów.
W ten sposób Twój zespół pozostaje zwinny, unika zamieszania buzzwordami i skupia się na dostarczaniu skalowalnego wpływu.
UWAGA: Ten wpis oparty jest na badaniach Inuits.it i Curioz.io i został opublikowany na obu platformach.
Chcesz z nami współpracować?
Porozmawiajmy o tym, jak możemy pomóc Twojemu zespołowi dostarczać szybciej.
Komentarze
Podziel się swoimi przemyśleniami.


