Od pipeline’ów do wypłat: inżynierowie danych w Polsce w 2025 roku

Przesuwaj dane, kształtuj rynek
Data engineers przeszli z zaplecza do sali konferencyjnej. Na polskiej scenie tech w 2025 roku to budowniczowie infrastruktury gotowej na AI, łączący chmurę, streaming i governance, aby modele nie tylko działały, ale się skalowały. Od fintechu i telekomunikacji po gaming, retail i opiekę zdrowotną – pracodawcy polują na talenty, które potrafią projektować odporne pipeline’y, porządkować chaotyczne dane i dostarczać niezawodne features w (bliskim) czasie rzeczywistym.

Źródło: Databricks Press Release
Z AWS Glue, Databricks, i Azure jako domyślnym stosem oraz Airflow, Astronomer i dbt obsługującymi orkiestrację, sygnały rynkowe są jasne: firmy chcą inżynierów, którzy potrafią szybko wdrażać, zachowywać zgodność i utrzymywać dane blisko czasu rzeczywistego. Ta rola nie jest już "wsparciem backendu"; to frontowy enabler prędkości produktu, dokładności AI i strategii biznesowej.
Wykute doświadczeniem
Polski rynek inżynierii danych jest przekształcany przez adopcję AI i przenoszenie bardziej złożonych projektów do lokalnych zespołów. Popyt rynkowy na data engineerów pokazuje, że firmy skalują się szybko, ale w sposób stawiający doświadczenie na pierwszym miejscu – stawiając na sprawdzonych profesjonalistów, zamykając drzwi większości juniorów.
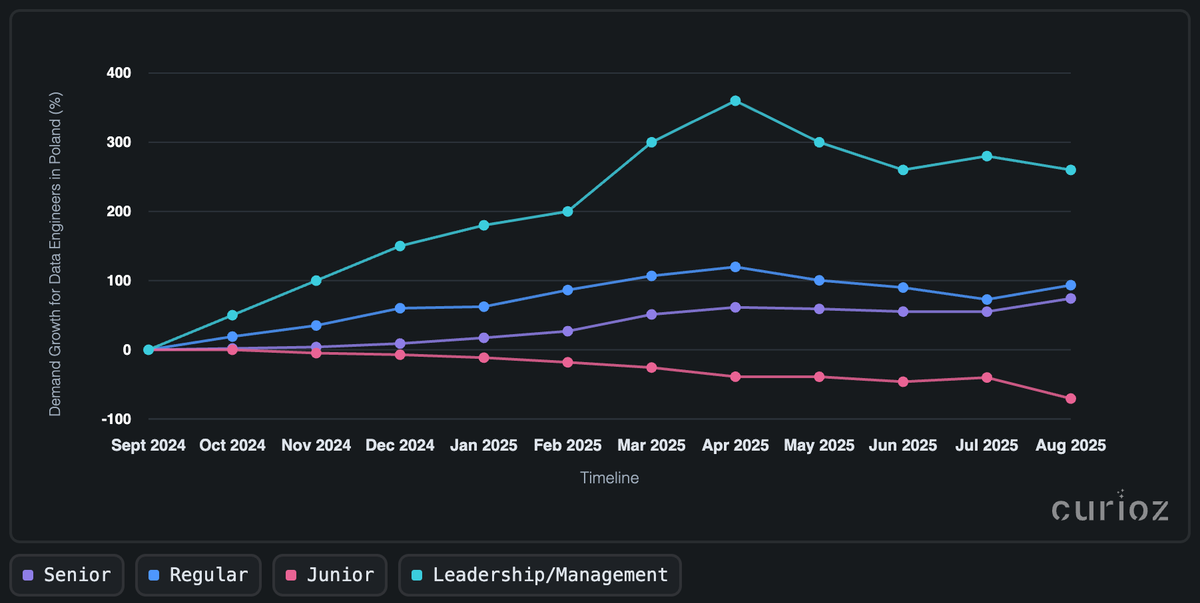
Metodologia i linia bazowa: Curioz dane oparte na ogłoszeniach o pracę i podpisanych kontraktach. Wrzesień 2024 jest linią bazową, wszystkie dalsze ruchy są mierzone względem tego miesiąca.
Role Regular poprowadziły ekspansję, stabilnie rosnąc przez wiosnę i osiągając szczyt na poziomie +120% w kwietniu 2025, po czym osłabły, ale wciąż są silne na poziomie +90% do sierpnia. Popyt na seniorów podążał równolegle, od płaskiego wzrostu do +50% w marcu do sierpnia 2025 – późnoletnie ponowne przyspieszenie popytu na doświadczonych inżynierów.
Natomiast popyt na juniorów stabilnie spada, osiągając dno około -70% do sierpnia. Oferty liderskie wzrosły o ~300% rok do roku, gdy złożone inicjatywy AI zakorzeniają się w Polsce. Firmy koncentrują zatrudnienie na seniornych IC i liderach, zaostrzając drogę wejścia dla juniorów i ograniczając rekrutację na poziomie początkującym.
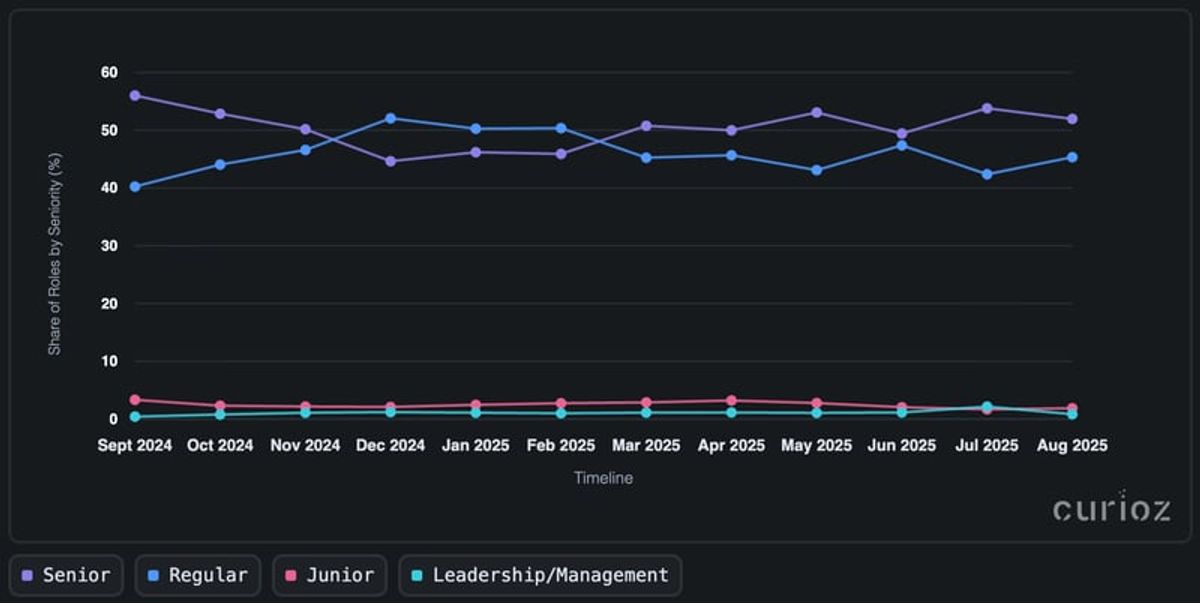
Do czego sumuje się ten wzór wzrostu?Patrząc konkretnie na oferty pracy, struktura rynku odzwierciedla jego dynamikę: seniorni inżynierowie konsekwentnie stanowią około 50% ról, podczas gdy Regular stanowiska odpowiadają za ponad 45%. Ten miks ponownie potwierdza, że firmy skalują się z doświadczonymi talentami, a nie rozszerzają się na poziomie początkowym.
Metodologia: Curioz dane z ogłoszeń o pracę i podpisanych kontraktów. Miesięczne udziały według seniorności obliczane są jako procent każdego poziomu względem całkowitej liczby rekordów.
Role juniorskie ponownie pokazują trend spadkowy, spadając z nieco ponad 3% pod koniec 2024 do poniżej 2% całkowitego wolumenu do lata 2025. Ten spadek sygnalizuje, że poprzeczka wejścia rośnie, prawdopodobnie dlatego, że organizacje pod presją dostarczania projektów AI mają niewiele miejsca na szkolenie pracowników na początku kariery. Pozycje liderskie utrzymują stabilny ~1% udział, z krótkotrwałym wzrostem podczas lipcowego spadku wolumenu, co sugeruje, że popyt na liderów nie jest źródłem wahań rynkowych. Udział proporcjonalny zmienia się niewiele, nawet gdy całkowity wolumen ogłoszeń rośnie.
Podsumowując, linie trendu pokazują rynek, który rośnie wolumenowo, ale nie strukturalnie: ciężar spoczywa zdecydowanie na rolach seniorskich i Regular. Rosnąca adopcja AI wzmacnia ten wzór, ponieważ skalowanie pipeline’ów danych i zapewnianie governance wymaga umiejętności skoncentrowanych w profilach mid-to-senior. Jednocześnie popyt na pozycje liderskie zaczyna rosnać, chociaż z małej bazy, aby kierować tymi inicjatywami, podczas gdy juniorzy pozostają na bocznym torze.
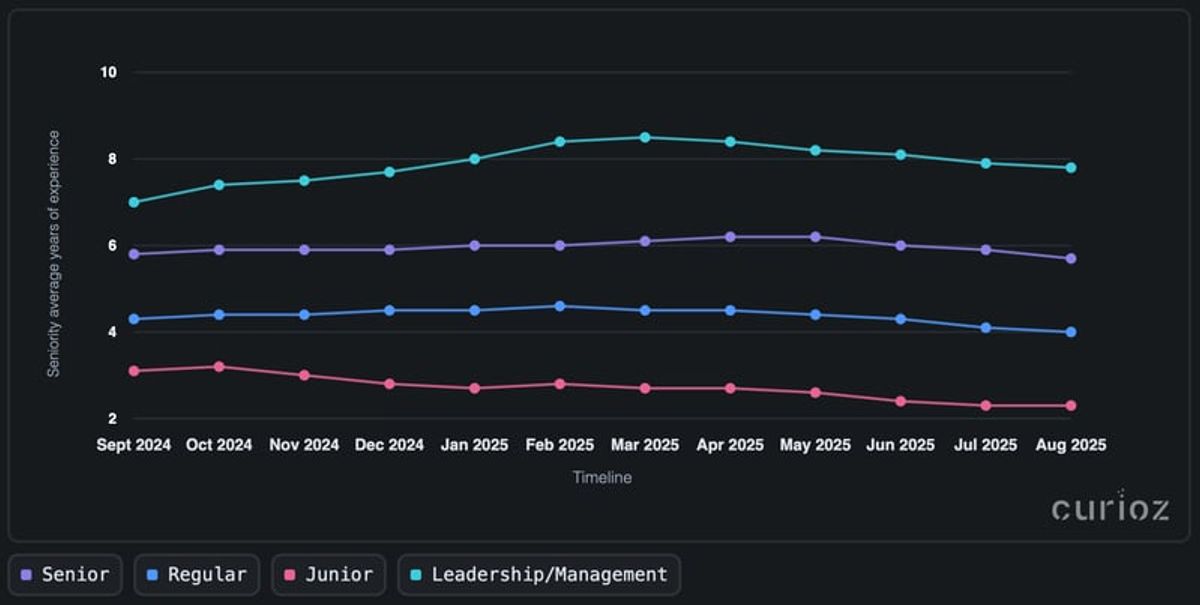
Mniej lat, te same tytuły
Curioz dane pokazują, że rynek przechyla się w kierunku doświadczenia na górze, jednocześnie usprawniając pozostałe poziomy. W miarę jak coraz więcej złożonych programów AI i danych prowadzonych jest z Polski, firmy potrzebują lokalnych szefów inżynierii do zarządzania architekturą, zgodnością i dostarczaniem, utrzymując popyt na liderów na podwyższonym poziomie. Role seniorskie są rekalibrowane, ponieważ dojrzałe stosy chmurowe i danych skracają krzywą uczenia się, a firmy priorytetyzują czas do wpływu, poszerzając kohortę seniorów nawet gdy wymagane lata spadają. Punkty wejścia juniorów są ściśnięte przez automatyzację i regulowane obciążenia, skłaniając zespoły ku mniejszym, ciężkim seniorsko składom.
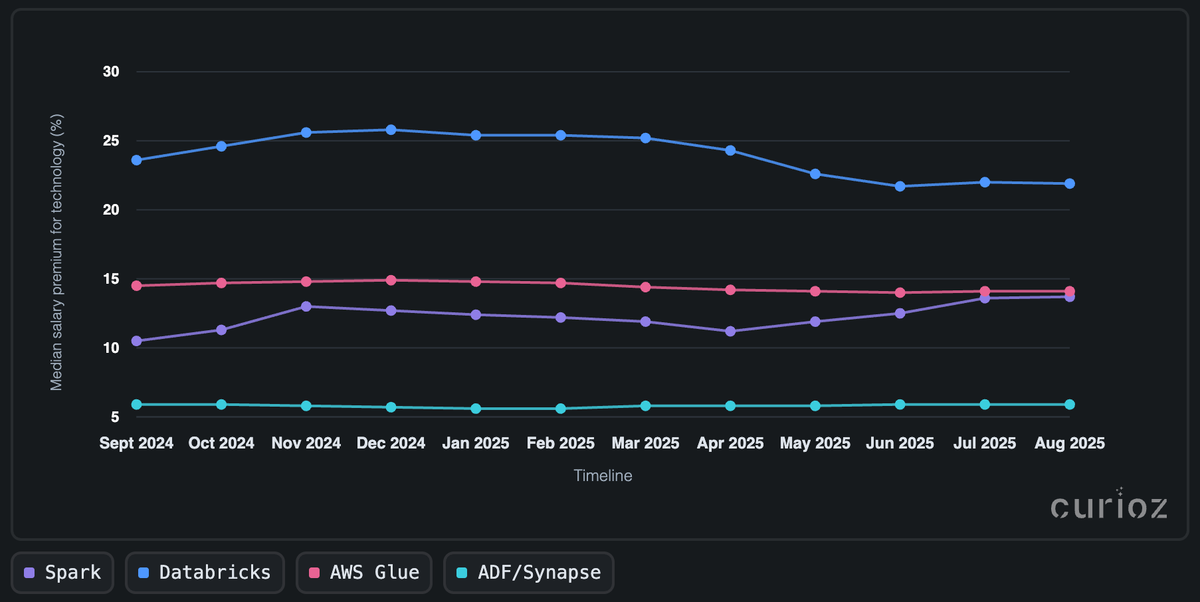
Inżynieria danych płaci premie
Dynamika wynagrodzeń pokazuje, jak doświadczenie, umiejętności i specjalizacja platformowa przekładają się na premie rynkowe, z wyraźnymi różnicami między rolami i technologiami. Dla seniornych Data Engineers na B2B w Polsce premie platformowe pokazują wyraźne poziomy:
- Databricks: wciąż na szczycie stosu. Osiągnął szczyt na poziomie +25,8% (grudzień '24) i osłabł do +21,9% (sierpień '25), słabnąc, ale wciąż dominując.
- Spark: historia powrotu. Wspinał się przez 2025 do nowego szczytu +13,7% (sierpień), odwracając ubiegłoroczny spadek i sygnalizując odnowiony popyt na umiejętności przetwarzania rozproszonego.
- AWS Glue: stabilny środek. Ledwie się poruszył (~14,9% → 14,1%), odzwierciedlając stabilny popyt ETL bez zmienności większych platform.
- Azure ADF/Synapse: niska, ale przewidywalna premia, utrzymująca się stabilnie na poziomie +5,6–5,9% – dowód na szerokie dostępności umiejętności i cieśniejsze marże.
Linia bazowa: Curioz mediana ~160 PLN/h dla Senior Data Engineer na kontrakcie B2B, bez specyfikowania technologii poza Python.
Podsumowując, Databricks wciąż płaci najlepiej, ale trend spada od szczytu pod koniec 2024; Spark jest grą na wzrosty, budującym impet do połowy 2025; Glue to niezawodny średniak nastoletniej półki; a ADF/Synapse nadal oferuje jedynie niewielką, przewidywalną dopłatę. W miarę jak otwarte formaty tabel, takie jak Apache Iceberg, rozprzestrzeniają się w tych stosach, premia coraz bardziej trafia do inżynierów, którzy potrafią projektować przenośne, zarządzane tabele lakehouse, utrzymując przewagę platformy Databricks, wzmacniając znaczenie Spark, utrzymując Glue na stabilnym poziomie i umiarkowanie podnosząc linię bazową w środowiskach Azure.
Dane na poziomie sali konferencyjnej, prędkość na poziomie seniora
Ten obraz jest poparty badaniami i analityką Curioz , które pokazują, że inżynieria danych przesunęła się z kulisowego wsparcia na centralną scenę podejmowania decyzji. Doświadczeni inżynierowie dostarczają gotowe na AI, zarządzane dane w bliskim czasie rzeczywistym na Databricks, Azure i AWS Glue, orkiestrowane z Airflow i dbt w sektorach fintech, telekomunikacji, gamingu, retailu i opieki zdrowotnej. Rekrutacja pozostaje nastawiona na doświadczenie: role Regular utrzymywały się na podwyższonym poziomie przez lato, popyt na seniorów ponownie przyspieszył, pozycje liderskie utrzymały stabilny udział w ogólnej seniorności, ale wzrosły wolumenowo 3-krotnie rok do roku, a juniorzy skurczyli się do marginesu, gdy AI automatyzuje rutynową pracę buduj i utrzymuj oraz przyspiesza "lata-do-tytułu".
Doświadczenie to premia, a seniorzy teraz siedzą w centrum polskich danych i AI na poziomie sali konferencyjnej.
Firmy wyraźnie przenoszą bardziej złożone, regulowane procesy o dużym wpływie do Polski, przesuwając miks talentów w kierunku doświadczonych profesjonalistów i praktycznych liderów, którzy potrafią projektować, zarządzać i skalować platformy. Sygnały płacowe odzwierciedlają wartość platform: Databricks zachowuje malejącą premię od poziomów z końca 2024, impet Spark odrodził się w 2025, AWS Glue pozostaje stabilną dopłatą średniego szczebla, a ADF/Synapse dodaje niewielką, przewidywalną premię. Tymczasem otwarte formaty tabel, takie jak Apache Iceberg, nagradzają inżynierów, którzy dostarczają przenośne, zarządzane dane lakehouse, które zwiększają ROI, ograniczają uzależnienie od dostawcy i utrzymują seniornych IC centralną rolę w prędkości produktu, dokładności AI i kontroli kosztów.
Data Engineer idealnie pasuje do Talent-as-a-Service (TaaS)
Większość 2025 roku to pipeline’y danych w czasie rzeczywistym, architektury gotowe na AI, zautomatyzowane transformacje i analityka predykcyjna na skalę. To dokładnie miejsce, w którym Data Engineer z nowoczesnymi stosami (Spark/Flink/Kafka/DBT/Cloud-native)i wbudowanymi zabezpieczeniami się wyróżnia.
Dlaczego potrzebujesz Data Engineer, aby utrzymać konkurencyjność?
- zwiększ dostępność danych i szybkość dostarczania (dni → tygodnie, nie kwartały);
- obniż koszty storage i compute → lepsze marże i szybsze wnioski;
- zamień surowe dane w dźwignię (pipeline’y feature’ów AI/ML powiązane z KPI);
- buduj bezpieczne, zgodne pipeline’y z zabezpieczeniami governance od pierwszego dnia;
- pozostan elastyczny narzędziowo wobec Spark, Kafka, DBT, Airflow i platform chmurowych, aby uniknąć uzależnienia od dostawcy.
Wzorzec współpracy TaaS (30/60/90)
- 0–30 dni: odkrywanie → bazowe KPI, prototypy, audyt gotowości, strategia danych;
- 31–60 dni: rozszerzanie pipeline’ów, dodawanie zabezpieczeń, integracja z CI/CD, obserwowalnością i data warehouse, pilotaż z użytkownikami;
- 61–90 dni: wdrożenie produkcyjne, optymalizacja kosztów/wydajności, monitoring i dashboardy jakości, runbook operacyjny.
Konkurenci już działają. Dodaj TaaS QA Automation Engineer teraz, aby utrzymać przewagę i kumulować ją z każdym sprintem.
UWAGA: Ten wpis oparty jest na badaniach Inuits.it i Curioz.io i został opublikowany na obu platformach.
Chcesz z nami współpracować?
Porozmawiajmy o tym, jak możemy pomóc Twojemu zespołowi dostarczać szybciej.
Komentarze
Podziel się swoimi przemyśleniami.


